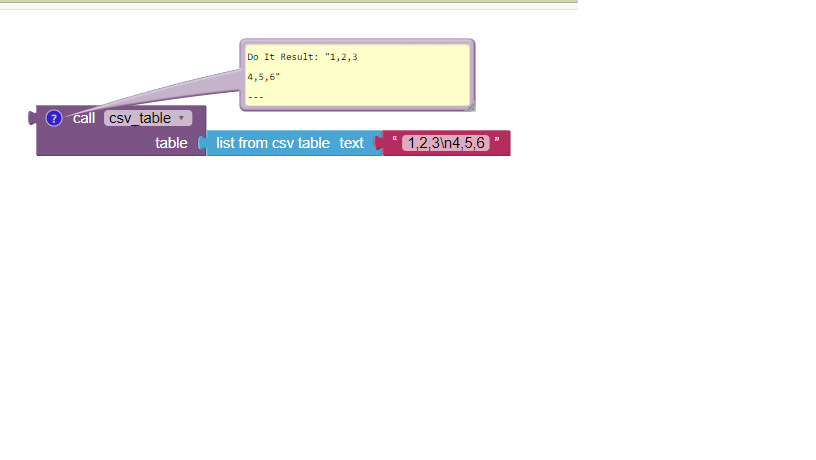
This is what the CSV looks like to me:

Interesting that even a form of declination pattern appears in spreadsheet format - but that's beside the point.
This is what the CSV looks like to me:
I thought the line breaks were some kind of pagination.
How do you get column number from the JSON?
And what does the column number mean?
I'm following a pretty basic process of columns being longitude ranging from -180 to 180 degrees and rows being latitude ranging from -85 to 85 degrees.
See my note above regarding the API glitch i'm experiencing WRT latitudes at the poles.
I can share the Python code that I used previously to scrape the CSV. It uses a cascaded loop to sequentially populate the csv. A bit inefficient and API call hungry.
You'll need to register your own API key if you want to run it.
import math
import json
import sys
import urllib.request
import os
SAMPLING_RES = 5
SAMPLING_MIN_LAT = -90
SAMPLING_MAX_LAT = 90
SAMPLING_MIN_LON = -180
SAMPLING_MAX_LON = 180
def constrain(n, nmin, nmax):
return max(min(nmin, n), nmax)
LAT_DIM=int((SAMPLING_MAX_LAT-SAMPLING_MIN_LAT)/SAMPLING_RES)+1
LON_DIM=int((SAMPLING_MAX_LON-SAMPLING_MIN_LON)/SAMPLING_RES)+1
# Declination
params = urllib.parse.urlencode({'lat1': 0, 'lat2': 0, 'lon1': 0, 'lon2': 0, 'latStepSize': 1, 'lonStepSize': 1, 'magneticComponent': 'd', 'resultFormat': 'json'})
#key=sys.argv[1] # NOAA key (https://www.ngdc.noaa.gov/geomag/CalcSurvey.shtml)
key="*****"
f = urllib.request.urlopen("https://www.ngdc.noaa.gov/geomag-web/calculators/calculateIgrfgrid?key=%s&%s" % (key, params))
data = json.loads(f.read())
print('Downoading declination data and writing to file. Please wait...')
with open("DeclinationTable.csv", mode='w') as f: #creates a new csv file "w" overwrites any previous file.
for latitude in range(SAMPLING_MIN_LAT, SAMPLING_MAX_LAT+1, SAMPLING_RES):
params = urllib.parse.urlencode({'lat1': latitude, 'lat2': latitude, 'lon1': SAMPLING_MIN_LON, 'lon2': SAMPLING_MAX_LON, 'latStepSize': 1, 'lonStepSize': SAMPLING_RES, 'magneticComponent': 'd', 'resultFormat': 'json'})
f = urllib.request.urlopen("https://www.ngdc.noaa.gov/geomag-web/calculators/calculateIgrfgrid?key=%s&%s" % (key, params))
data = json.loads(f.read())
with open("DeclinationTable.csv", mode='a') as f: #"a" means to append - this will write each line, one after the other.
f.write(' ')
for p in data['result']:
# declination in radians * 10^-4
declination_int = constrain(int(round(math.radians(p['declination'] * 10000))), 32767, -32768)
f.write('{0:6d},'.format(declination_int))
f.write("\r")
print('Latitude: ',[latitude])
print('Finished.')
os.system('pause')
Is the 360/5 = 72 column format a real requirement, or is it inheritted, like
?
It could be 360/10.
Because i'm processing the data in-app using bilinear interpolation I felt like 5 degrees was an easily manageable dataset size and would provide a good degree of accuracy through interpolation.
I've not undertaken a strict analysis comparing the WMM against my interpolation method to determine the sweet spot.
That wide format for the csv makes it harder to filter, compared to a 3 column (lat,long,decl) format.
Were you planning on carrying around printed wallpaper charts from that csv?
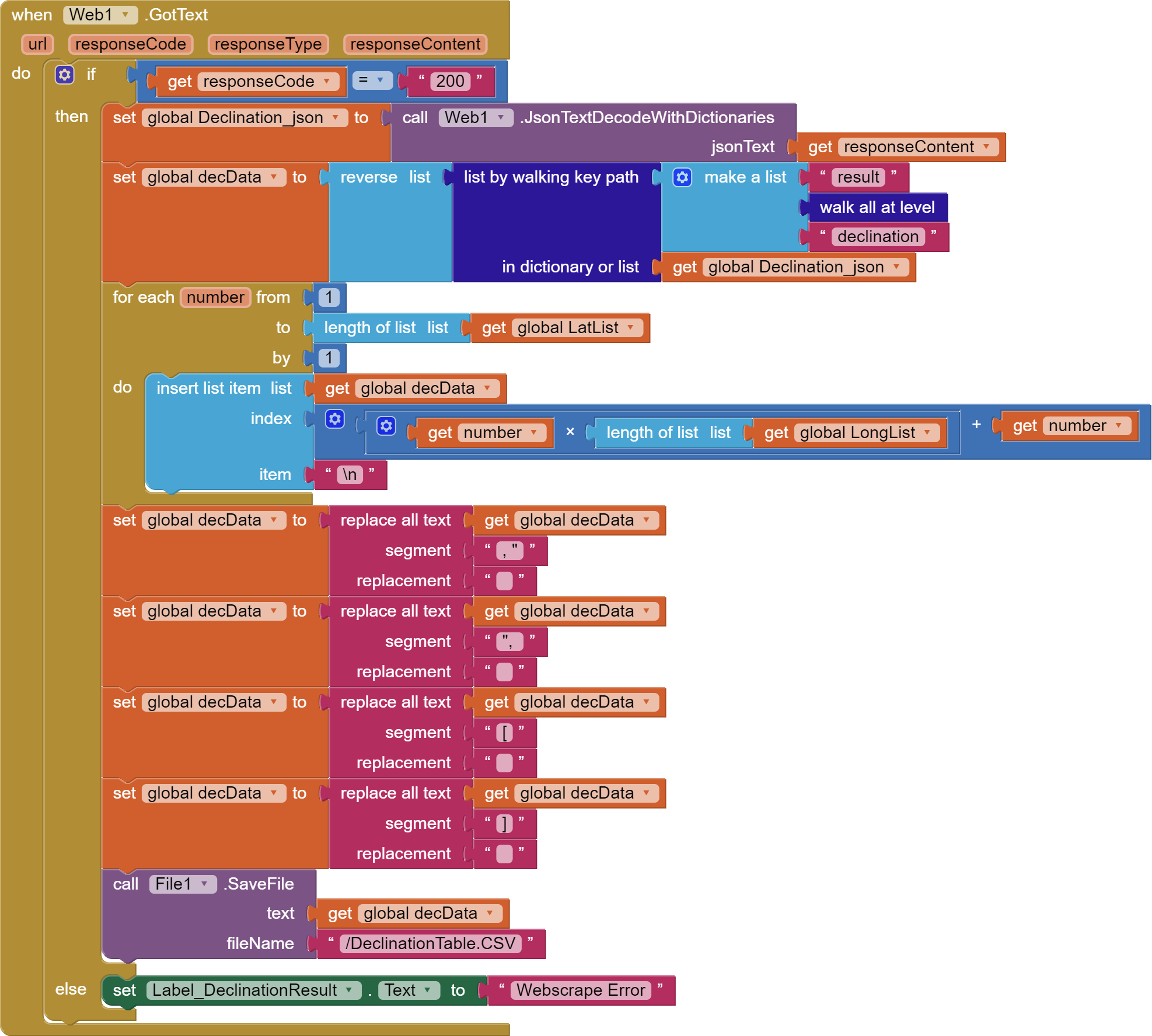
I'm not sure you've picked up on how the data is being used in the next steps if the process. Please refer to this method I've been using successfully:
Sorry, this is a deeper dive than I expected.
Maybe tomorrow for me.
Yeah, it's fairly novel in this space from the limited resources i've been able to piece together. I'm confident that we as a community will get there with the simplest and easily understandable approach though.
I've perservered with my original approach and have been able to format the output CSV as required. It follows this general approach:
I feel a little bit grubby on the inside as I feel like there is a better approach here, but it's working and doing so simply.
The only issue now is that my CSV table needs to be flipped on a vertical line. The -180 longitude is currently on the leftmost column and the the 180 longitude in on the right. It needs to be the other way around. I tried to change this with the API but it only allows +ve increments to the latitude/longitude values.
I'll either need to resolve this flip here or change the next phase of bilinear interpolation code to suit the flipped CSV.
Thanks @ABG.
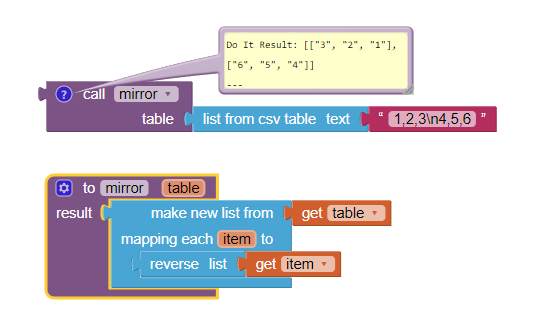
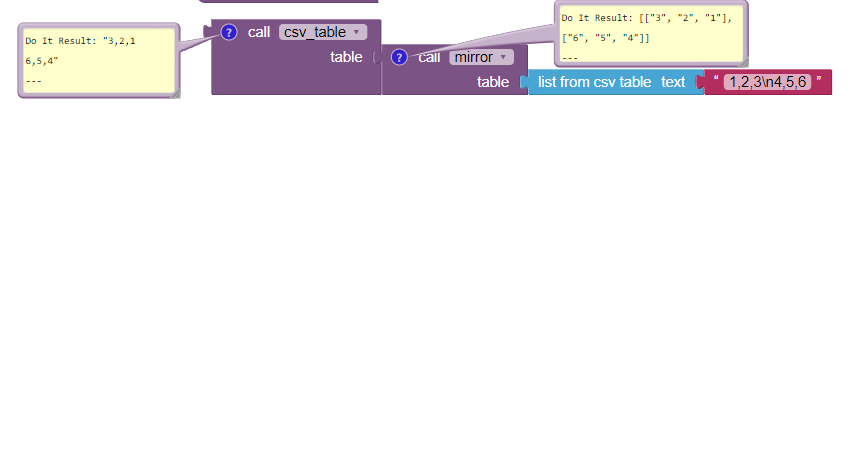
When I integrated the JSON scrape into my Bilinear Interpolation code I'd shared earlier, I realised that all I needed to do was change the way the interpolation code reads the data in. Instead of reading it in descending order (180 degrees through to -180 degrees), I simply told it to read it as if it was ascending (-180 degrees through to 180 degrees). Ultimately, no need to compute a mirror.
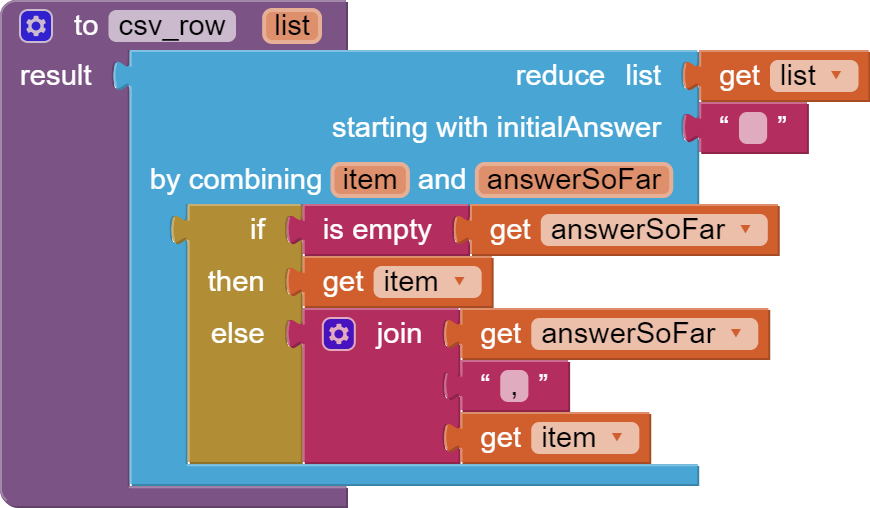
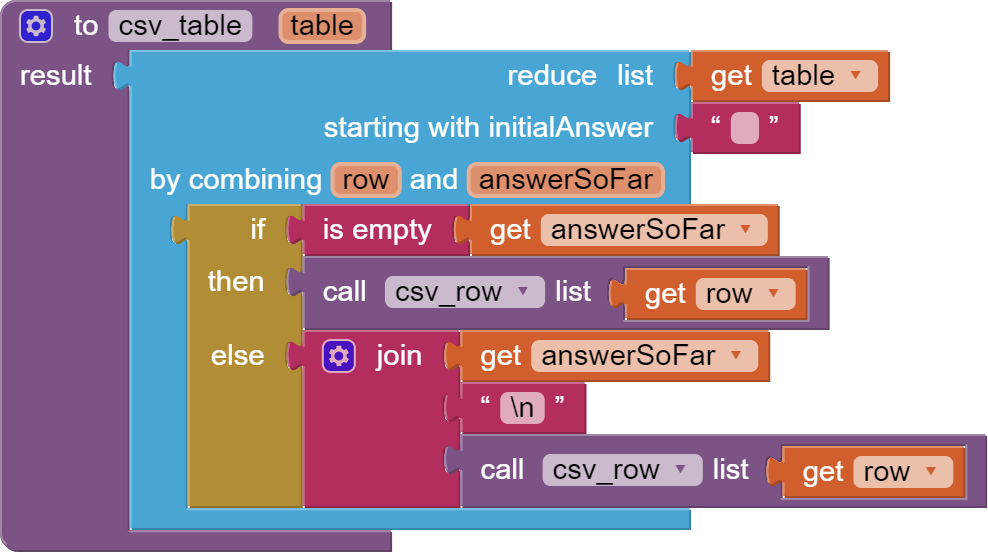
My biggest gripe right now is the way I translate my long, single list (from the API scrape) into a multi-line string for saving as a CSV and then reloading to convert it back to a list of lists using the "list from csv table" block. It's very clunky.
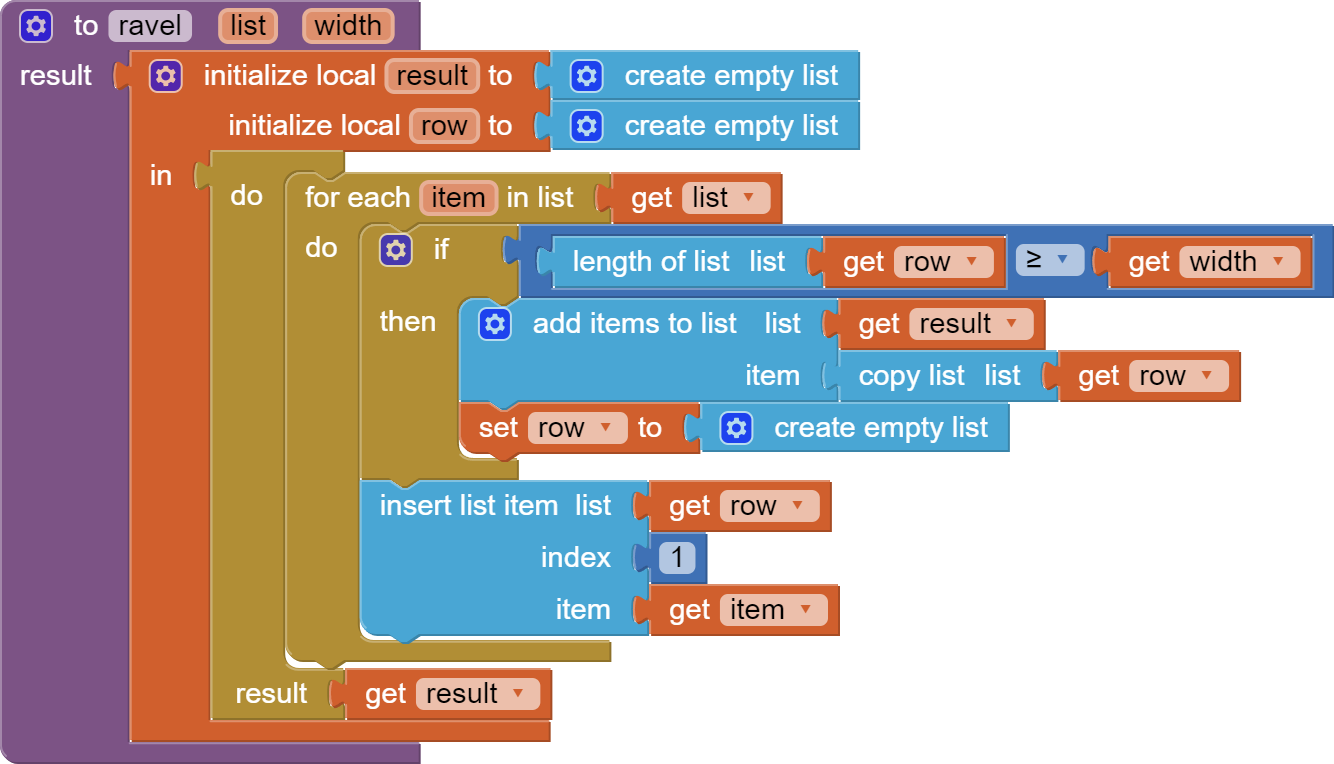
Ideally, I'd "simply" write a procedure that parses a single list into a list of lists of X*Y dimensions. If anyone has any ideas on this, you're most welcome to share.
Thank you. It works as expected. I see the blocks add each item from the long list into a temporary list until it reaches the width parameter and then it adds those items to a new output list, repeating until all of the items in the original list have been parsed.
Now. I'm grappling with a way to save the list of lists externally using my original plan which was as a CSV (essentially a text file). But I feel this approach might not be appropriate anymore because saving my list of lists to a text string depreciates the list i.e. I can't simply write a string to a file in the "format" of a list and expect the system to interpret the string as a list when I load it back in.
I should probably be using something like a TinyDB to save the list of lists. I think @TIMAI2 's post here might give me what I need. I'll review and try to understand that to see how it goes and report back.
Reporting back. I think i'm at the end of this thread with a great outcome.
Simply storing my API scraped JSON data as a list of lists, stored in a TinyDB has provided the best outcome. No need to convert the JSON to CSV and back to a list - that was only creating more work that didn't need to be done.
Always good to stop, take stock and ask yourself (numerous times) "why am I doing this"?
Thank you @ABG for sticking with me through this thread and providing your guidance.
Note on my ravel value procedure:
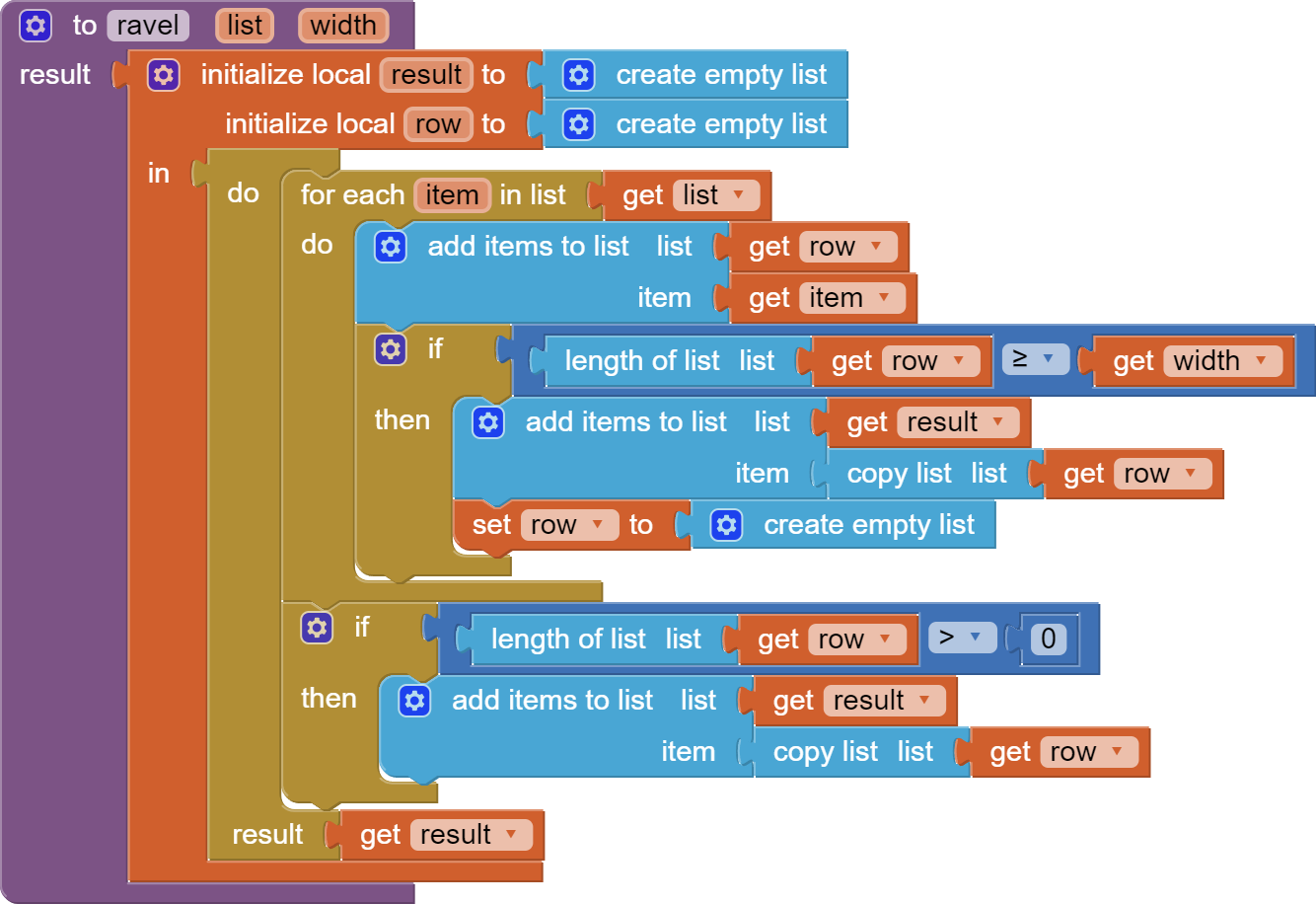
I was losing the last row, and should have been doing the mirror operation in a separate procedure.
For the record, here is my hopefully final version:
Thank you. I probably would never have noticed unless I took the app close to the South Pole or had otherwise pressure-tested it manually! 
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.